

Key Takeaways
- Today's AI agents are amnesiac, discarding valuable execution data after each task. This is the single greatest inefficiency in the current AI stack.
- A new paradigm, "Self-Evolution," is emerging from top research labs. Agents learn from past successes and failures by extracting reusable "skills" or "principles" into a persistent memory bank.
- This evolution happens without retraining the base LLM (e.g., GPT-5), making agents smarter, faster, and more efficient over time through experience.
- Standard vector databases are insufficient for this task. They lack the structural integrity to store causal relationships, complex procedures, and hierarchical skills.
- The critical enabling infrastructure is a Semantic Graph, which combines vector search with a structured graph database. This is the foundation of Epsilla's architecture.
- The ultimate competitive moat in the AaaS (Agent-as-a-Service) landscape of 2026 will not be the base model, but the proprietary, evolved memory of your agent fleet, managed and governed through a platform like Epsilla's AgentStudio.
We are at a strategic inflection point in the development of artificial intelligence. For the past few years, the dominant narrative has been a brute-force arms race: larger models, more parameters, bigger context windows. While the raw power of models like GPT-5 and Claude 4 is undeniable, this approach is hitting diminishing returns. The true frontier, the one that will separate fleeting novelties from enduring enterprise value, is not in the models themselves, but in what happens between the model's inferences. It's about memory. Specifically, it's about building agents that learn, adapt, and evolve from their own experiences.
The current state of AI agents is, to be blunt, profoundly inefficient. An agent, powered by a state-of-the-art LLM, is tasked with a complex multi-step problem. It plans, executes, uses tools, perhaps fails, backtracks, and eventually succeeds. It generates a rich, detailed execution trace—a log of every thought, action, and outcome. And then, upon completion, we throw it all away. The agent starts its next task as a blank slate, a newborn with the intellect of a genius but the memory of a goldfish.
This is an act of colossal data vandalism. We are systematically incinerating the most valuable, context-rich training data imaginable: the agent's own lived experience. As a founder, this is the kind of waste that should keep you up at night. It’s like hiring the world's most brilliant consultant for a project, and then wiping their memory clean the moment they deliver the final report. The next time you hire them, they have to re-learn everything about your company, your market, and the project's constraints from scratch. It's untenable.
The Paradigm Shift: From Amnesia to Evolution
A new wave of research is finally addressing this fundamental flaw. The consensus emerging from the most forward-thinking labs is that the future is not about constantly retraining monolithic models. It's about creating a persistent, evolving memory layer that allows an agent to accumulate wisdom over time. This is the concept of Self-Evolution.
The core idea is simple but profound: instead of discarding execution traces, the agent analyzes them to distill high-level, reusable "skills," "principles," or "heuristics." These distilled insights are then stored in a dedicated memory bank. Before tackling a new task, the agent queries this memory bank for relevant past experiences, effectively bootstrapping its problem-solving process with accumulated wisdom. A failed attempt to parse a specific API's error message becomes a durable "skill" for handling that error in the future. A successful sequence of commands for setting up a cloud environment becomes a reusable "principle" for infrastructure deployment.
This is not fine-tuning. Fine-tuning modifies the model's weights, a costly and slow process. Self-evolution is a higher-level cognitive loop that operates on top of a static base model. The agent's core intelligence (the LLM) remains unchanged, but its effective performance improves dramatically as its library of learned experiences grows.
Architectural Blueprints for Evolving Agents
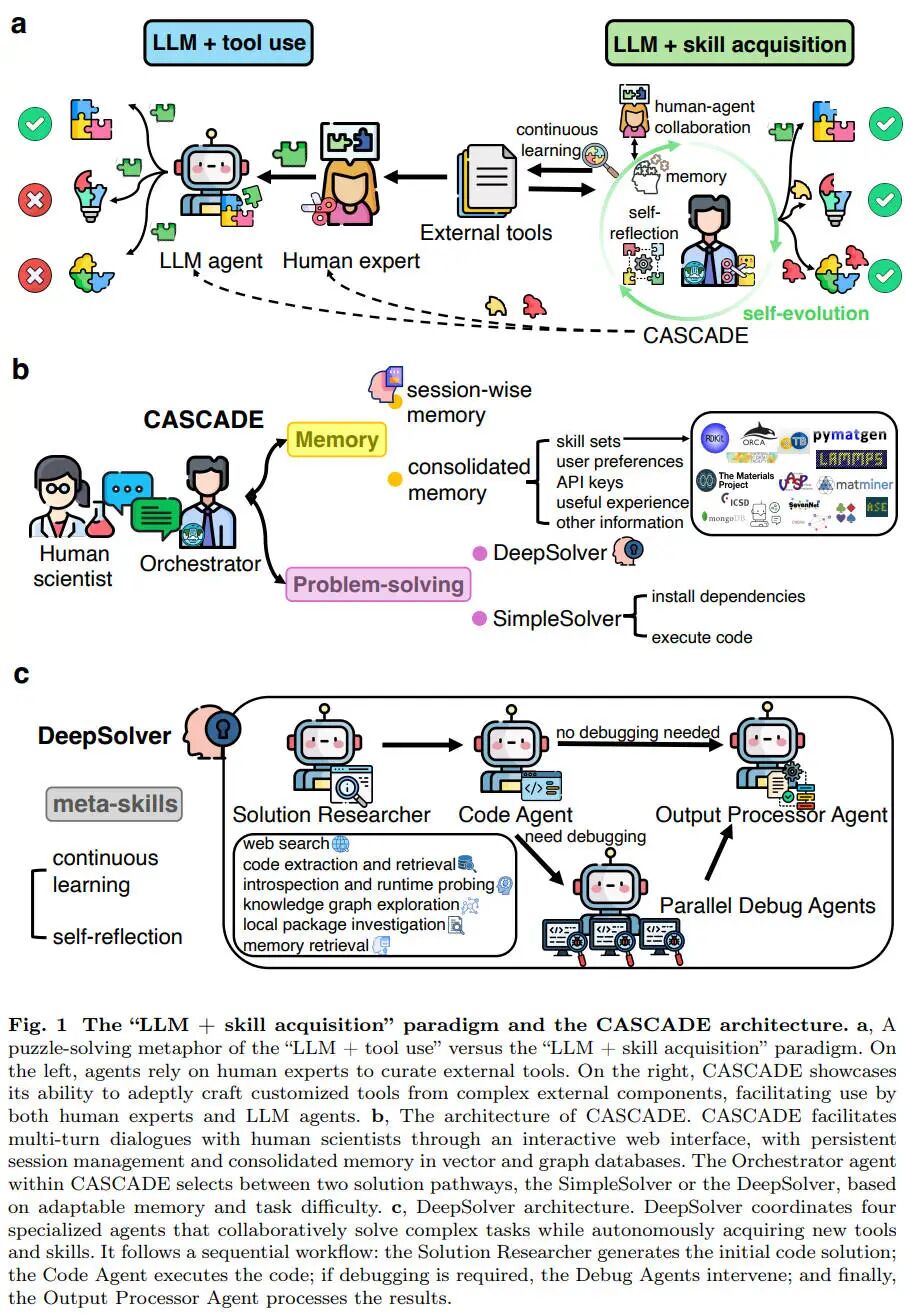
Three recent research frameworks—EvolveR, CASCADE, and STELLA—provide a clear blueprint for how this will work in practice. While they differ in their specifics, they share the same philosophical core: extract, store, and reuse experiential knowledge.
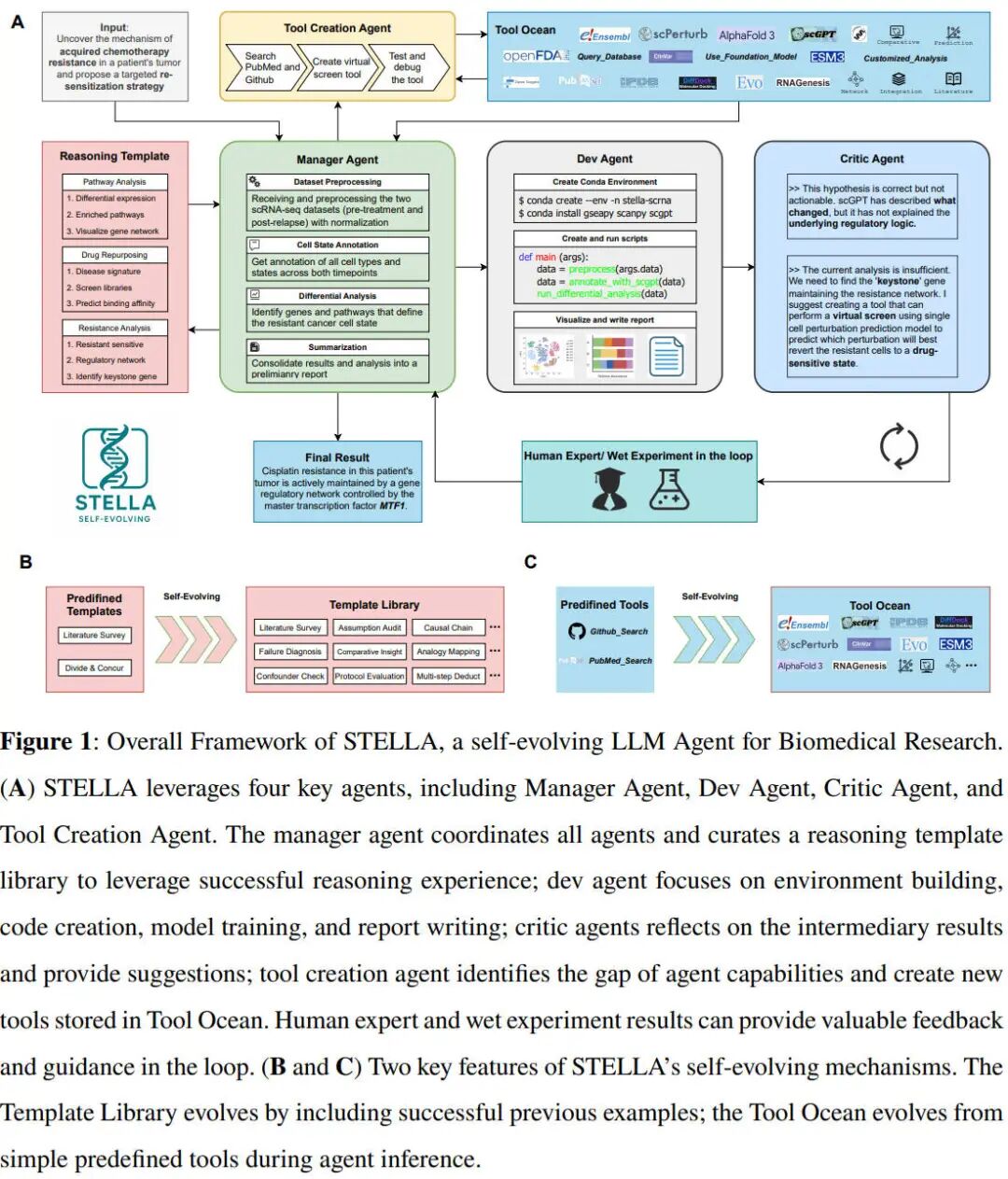
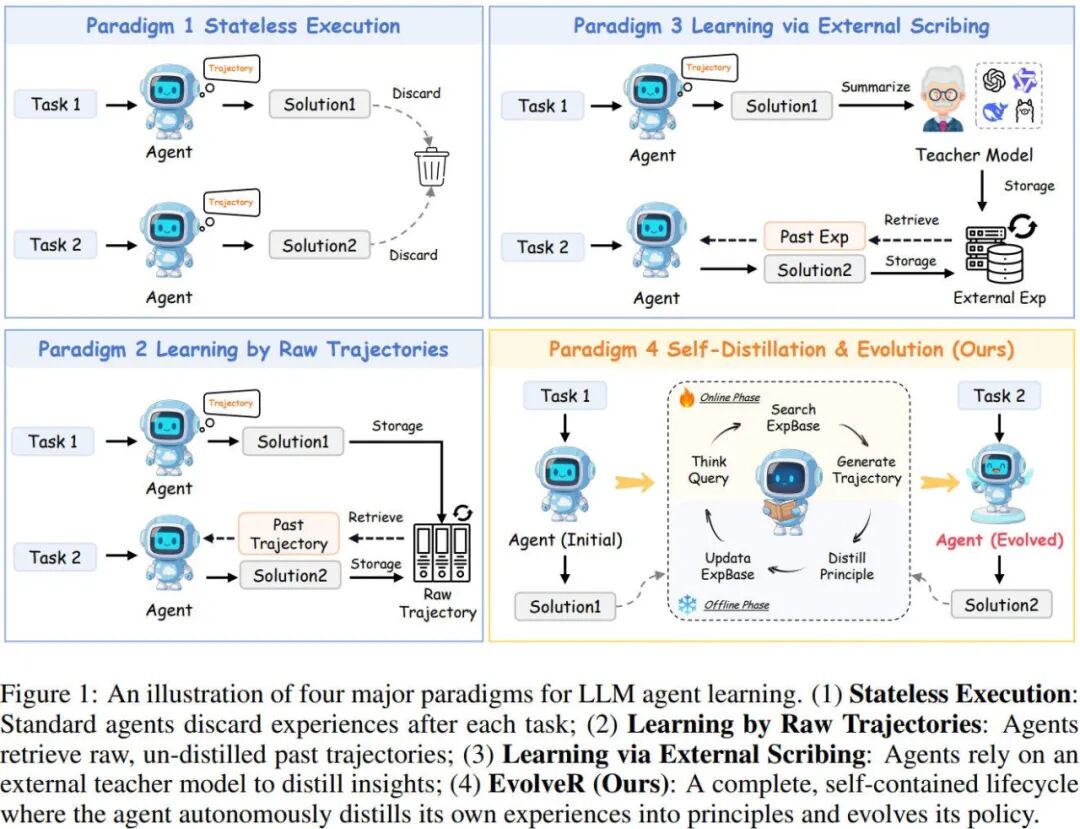
EvolveR focuses on distilling successful execution traces into generalized "principles." After a task is completed, a meta-agent analyzes the step-by-step log and generates a concise, high-level principle for success. For example, instead of remembering a hundred lines of code, it might generate the principle: "When deploying a web app on this platform, always provision the database before initializing the server to avoid connection timeouts." This principle is then stored and indexed.
The Enterprise Imperative: Why the Semantic Graph is the Only Path to Self-Evolution
The transition from stateless, single-run agents to continuous, self-evolving systems represents a fundamental shift in AI architecture. It forces us to confront a hard truth about enterprise data infrastructure: standard vector databases are entirely insufficient for the era of Agent-as-a-Service (AaaS). If an agent is to extract, store, and dynamically retrieve complex operational "skills" or "principles" derived from past execution traces, it requires a memory layer that understands structure, relationship, and hierarchy. It requires a Semantic Graph.
Consider the architecture proposed in the EvolveR framework. The offline distillation process abstracts concrete execution steps into generalized strategy principles. When a Claude 4 or GPT-5 agent encounters a new, complex multi-hop reasoning task, it must query its memory bank not just for semantic similarity, but for structural relevance. A traditional RAG (Retrieval-Augmented Generation) pipeline, reliant on dense vector embeddings, will retrieve snippets based on keyword overlap. It cannot differentiate between a raw error log, a hardcoded tool specification, and a highly abstracted, generalized operating principle.
Epsilla's Semantic Graph solves this exact architectural bottleneck. By organizing an enterprise's collective agent knowledge into a structured graph, we provide agents with a deterministic, traversable memory fabric. When an agent operating within AgentStudio fails a task, the resulting execution trace is ingested, analyzed, and the failure mode is codified as a negative constraint within the graph. When a subsequent agent tackles a similar workflow, the Semantic Graph routes the relevant principle to the agent's context window via the Model Context Protocol (MCP), ensuring the mistake is never repeated.
Furthermore, the concept of a shared "skill library," as explored in the CASCADE research, demands rigorous enterprise governance. If an agent autonomously generates a new data-extraction skill that interacts with internal HR systems, that skill cannot be globally accessible to all agents across the network. Epsilla’s AgentStudio enforces Role-Based Access Control (RBAC) at the graph level. The Semantic Graph ensures that self-evolved skills inherit the permissions of the data and systems they interact with. An agent operating in the marketing department cannot inadvertently invoke a skill distilled from the finance department's execution traces.
This level of granular control is the dividing line between experimental research and production-grade enterprise deployment. Self-evolution, without structural memory and RBAC, is a recipe for silent, catastrophic agent drift. A model that "learns" the wrong lesson from a hallucinated execution trace will poison its own capabilities if that lesson is blindly stored in a flat vector database and repeatedly retrieved in future runs. The Semantic Graph acts as the immune system, structuring knowledge, enforcing access boundaries, and providing the observability necessary for human operators to audit the evolution process via ClawTrace.
Ultimately, the research coming out of Stanford, Berkeley, and other top institutions in 2026 points to a future where base model performance (whether Llama 4 or GPT-5) becomes commoditized. The true intellectual property, the ultimate competitive moat for any enterprise, will be the accumulated, structured experiences and skills of its autonomous workforce. The Semantic Graph is the vault where that intellectual property is secured, organized, and deployed, transforming raw compute into compounding enterprise value.